
티스토리 뷰
안녕하세요. 죠쵸입니다.
오늘부터 본격적으로 Kaggle에서 진행되었던 경진대회의 데이터를 분석해 보고 시각화를 진행해 보도록 하겠습니다.

#타이타닉 머신러닝 경진대회 - Competition Overview
가장 먼저 볼 경진대회는 타이타닉 머신러닝 경진대회(Titanic: Machine Learning from Disaster)입니다. Kaggle의 타이타닉 경진대회는 실제 발생한 해상사고의 데이터를 기반으로 출제가 되었으며, 해당 경진대회로부터 Machine Learning의 기초적인 이론 및 실습을 해 볼 수 있습니다.
Kaggle - Titanic Competition : https://www.kaggle.com/c/titanic/
캐글 타이타닉 데이터 분석 및 시각화하기에 앞서서, Kaggle 경진대회는 어떻게 참가 할 수 있는지 아래의 영상을 통해서 참조 해 주세요.
영화로도 나와 잘 알려진 타이타닉이지만, 약간의 배경 설명을 통해 해당 경진대회의 기본지식을 쌓아보자.

RMS 타이타닉(통용: RMS 타이타닉, 영어: RMS Titanic)은 영국의 화이트 스타 라인이 운영한 북대서양 횡단 여객선이다. 1912년 4월 10일 영국의 사우샘프턴을 떠나 미국의 뉴욕으로 향하던 첫 항해 중에 4월 15일 빙산과 충돌하여 침몰하였다. 타이타닉의 침몰로 1,514명이 사망하였다.
RMS 타이타닉은 첫 항해 당시 세계에서 가장 큰 배 가운데 하나였다. 화이트 스타 라인 사는 RMS 올림픽을 시작으로 세 척의 올림픽급 여객선을 운용하였으며, RMS 타이타닉 역시 그 가운데 하나였다. RMS 타이타닉은 벨파스트에 있는 해럴드 앤 울프 사가 1909년 건조를 시작하여 1911년 5월 31일 진수하였다.
첫 항해에 오른 승객은 다양했으며 이 가운데에는 매우 부유한 사람들도 있었다. 대다수는 영국과 스칸다나비아 반도 등에서 새로운 삶을 찾아 미국으로 가는 이민자들이었다. 출항 당시 승선 인원은 2,223명이었다.
타이타닉호는 선내에 체육관과 수영장, 그외 호화로운 부대시설을 갖추고 있었다. 그런데 느슨한 규제 때문에 구명정은 20척 밖에 없었다. 구명정의 정원은 1,178명이었다. 1912년 4월 14일 오후 11시 40분(선내 시각, GMT -3)빙산과 충돌하였고 이 때문에 주갑판이 함몰되면서 우현에 구멍이 났다. 구멍으로 물이 들어오기 시작한 지 2시간 40분만에 완전히 침수되어 침몰하였다. 타이타닉호는 방수용 격벽이 설계되어 있었고 문들도 물을 차단할 수 있도록 설계되었으나 실제 사고에선 역부족이었다. 구명정에 타지 못한 채 바다로 뛰어든 수많은 사람들은 수 분 내에 저체온증으로 사망하였다. 침몰할 당시까지도 배에는 1,000여명의 사람들이 남아 있었다. 구명정을 타고 있다가 몇 시간 뒤에 RMS 카르파티아(RMS Carpathia)에 의해 구조된 사람은 706명에 불과하였다.
- WIKIPEDIA -
이 경진대회에 Target(Goal)은 "어떤 사람들이 생존 할 가능성이 더 높은가?" 라는 질문에 답하는 예측 모델을 구축하는 것이다. 승객 데이터 (예 : 이름, 나이, 성별, 사회 경제적 등급 등)를 이용하여 예측 모델을 구축하게 된다.
#타이타닉 머신러닌 경진대회 - Competition Data
해당 경진대회의 데이터는 아래의 링크에서 다운로드 받을 수 있습니다.
Kaggle - Titanic Competition Data - https://www.kaggle.com/c/titanic/data
1) Train set(train.csv) : 해당 데이터를 분석을 통해서 생존여부를 예측할 수 있는 모델을 만들 수 있습니다.
2) Test set (test.csv) : 만들어진 모델을 Test Data에 적용하여, 그 결과를 Kaggle에 제출하면, 모델의 성능을 확인 할 수 있습니다.
[Data Dictionary]
| Variable | Definition |
| Survival | 생존 여부 |
| Pclass | 티켓 클라스 |
| Name | 탑승자 이름 |
| Sex | 성별 |
| Age | 나이 |
| Sibsp | 탑승한 형제 자매 / 배우자 수 |
| Parch | 탑승한 부모 / 자녀의 수 |
| Ticket | 티켓 번호 |
| Fare | 요금 |
| Cabin | 케빈 번호 |
| Embarked | 승선지(항구) |
#타이타닉 머신러닌 경진대회 - Notebooks
1) Importing important libraries
# data analysis libraries
import pandas as pd
import numpy as np
# visualization libraries
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
# ignore warnings library
import warnings
warnings.filterwarnings("ignore")2) Reading the dataset
# PassengerId라는 컬럼을 인덱스(index)로 지정하여 train.csv 파일을 읽음
train = pd.read_csv("titanic/train.csv", index_col="PassengerId")
# 데이터의 행렬 사이즈를 출력 (row, column)
print(train.shape)
# 데이터의 상위 5개를 출력
train.head()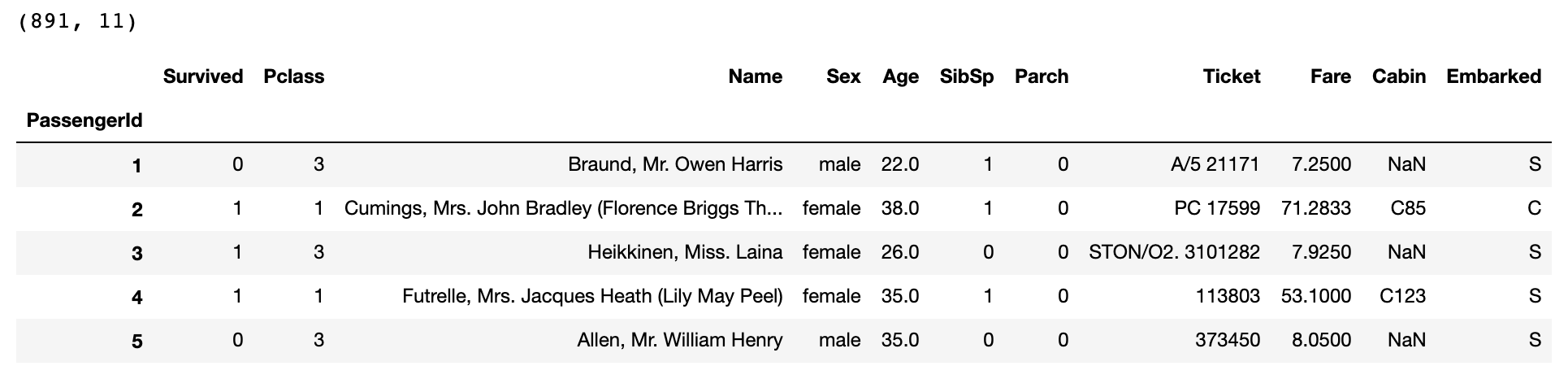
3) Exploratory Data Analysis(EDA)
탐험적 데이터 분석을 통해서, 데이터가 갖는 특성을 파악할 수 있습니다. 데이터의 특성을 파악하는 것은 곧 예측 모델을 만드는 과정에서 사용되기때문에, 성능이 좋은 모델을 만들기 위해서는 데이터의 특성을 파악하는 것은 중요합니다.
#데이터에 대한 기본정보를 확인
train.info()
#데이터가 비어 있는 항목 및 수량 확인
print(train.isnull().sum())
# 데이터셋 Summary 보기
train.describe()
4) Data Visualization
#value_counts 함수를 이용하여 생존자 인원과 사망자 인원을 확인
train["Survived"].value_counts()
#생존여부에 따라 신규 컬럼(Survived(humanized))에 Perish / Survived Value 삽입
train["Survived(humanized)"] = train["Survived"].replace(0, "Perish")
.replace(1, "Survived")
#Ticket의 Class에 따라 First Class / Business / Economy Value 삽입
train["Pclass(humanized)"] = train["Pclass"].replace(1, "First Class")
.replace(2, "Business")
.replace(3, "Economy")
#Ticket의 Class별 생존자수 / 사망자수를 그래프로 출력
sns.countplot(data=train, x="Pclass(humanized)", hue="Survived(humanized)")
Economy Class의 승객이 다른 Class의 승객보다 많은 사람이 구조되지 못하고 사망한 것을 알 수 있다.
#탑승지에 따라 신규 컬럼(Embarked(humanized)) Cherbourg / Southampton / Queenstown Value 삽입
train["Embarked(humanized)"] = train["Embarked"].replace("C", "Cherbourg")
.replace("S", "Southampton")
.replace("Q", "Queenstown")
#탑승지별 생존자수 / 사망자 수를 그래프로 출력
sns.countplot(data=train, x="Embarked(humanized)", hue="Survived(humanized)")
타이타닉에 탑승한 탑승객 중 많은 사람이 Southampton에서 탑승하였고, Southampton 탑승자 중 60%정도가 사망하였습니다.
#성별에 따른 생존자 수 / 사망자 수를 그래프로 출력
sns.countplot(data=train, x="Sex", hue="Survived(humanized)")
타이타닉의 탑승객 중 남자의 경우 구조된 사람보다 사망한 사람이 더 많고, 여자의 경우 구조된 사람이 사망한 사람보다 많은 것을 알 수 있습니다.
오늘은 간단히 Pclass, Embarked, Sex 컬럼을 통해서 분석한 내용을 보여 드렸습니다. 그 밖에 Fare, Age, Sibsp, Parch 컬럼을 통해서 더 많은 것을 분석이 가능합니다. 다음 글에서는 추가적인 데이터 분석과 예측 모델을 만들고, Machine Learning 알고리즘 중 하나인 Decision Tree를 통해서 Test 결과를 만들어 나가는 것을 쉽게 설명 하도록 하겠습니다.
오늘도 찾아 주셔서 감사합니다. 여러분의 공감하기와 구독은 저에게 힘이 됩니다.
좋은 하루 되세요. 이상으로 죠쵸이었습니다.
'Data Science' 카테고리의 다른 글
| Pandas(판다스)는 무엇인가? (11) | 2020.09.08 |
|---|---|
| 캐글 Bike Sharing Demand 데이터 분석 및 시각화 (1) | 2020.09.06 |
| 머신러닝은 무엇인가? (2) | 2020.08.28 |
| 캐글, 누구냐 넌? (0) | 2020.08.23 |
| 데이터 과학(Data Science)이란 ? (4) | 2020.08.17 |
- Total
- Today
- Yesterday
- 리바이스사이즈
- ap news
- 파이썬
- ai
- pandas
- Machine Learning
- Big Data
- joecho
- English
- 죠쵸
- 캐글
- kule
- 328. Odd Even Linked List
- Pandas(판다스)
- Leetcode
- 영어공부
- python
- 데이터 분석
- Kaggle
- 파이썬 기초
- 큘가방
- 판다스
- 파이썬 독학
- Leetcode255
- AdSense
- 리트코드
- 티파니T1
- Study
- 재귀함수
- 아디다스삼바화이트
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |